What is domIns all about?
DomIns is a web resource aimed at providing comprehensive information on domain insertions in proteins of known structure. We have followed the definition of protein domains as in the SCOP (Structural Classification of Proteins) database in order to identify insertions.


DomIns
A Web Resource for Domain
Insertions in Known Protein Structures
What are domain insertions?
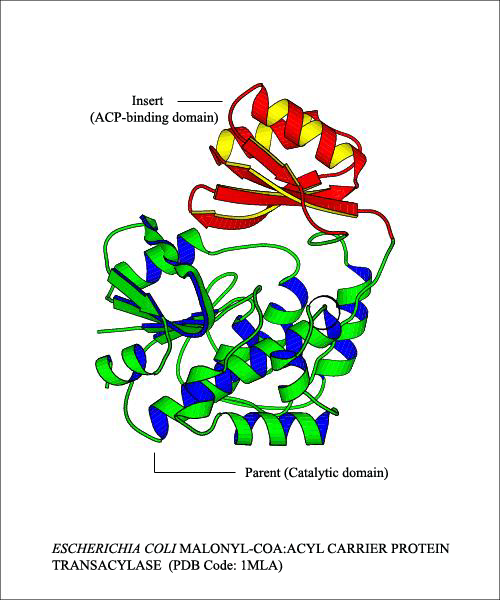
In the above figure, the E.coli protein Malonyl-CoA:Acyl Carrier Protein transacylase has two domains: the catalytic domain is interrupted by the insertion of the ACP-binding domain . The parent domain (catalytic domain) has two regions, with residue position from 3-127 and 128-307 in the same domain. Both the parent and the insert domains belong to two different superfamily of proteins. Similar arrangement is seen in Streptomyces coelicolor malonyl-CoA:ACP transacylase as well. This is an example for single insertion, where the parent domain is interrupted by a single insert domain. In mutiple insertions, there is more than one insert domain.
Access Methods
The information in the database can be accessed using different methods.

Browse by type of insertion
We have classified domain insertions based on the number of insert domains seen in a single chain. In single insertions, a domain belonging to a particular superfamily gets inserted into another domain of the same superfamily or of a different superfamily. In multiple insertions, more than one insert, of the same or different superfamily is inserted into the parent domain.
Browse all entries
All known domain insertions in PDB can be browsed individually.

Browse by combination
We have considered the first five classes in SCOP for determining domain insertions. Hence there are 25 possible combinations of parent-child combinations. This option allows the user to browse based on such combinations. For example, domain insertions where the parent belongs to alpha/beta class and insert belongs to alpha+beta class.

Search by PDB Code or keyword
A user can submit a PDB Code (eg., 1an9) with or without chain information or SCOP domain or keyword.
How does one identify domain insertions?
Although there are several schemes for protein structure classification for investigating protein sequences and structures, SCOP is important as it is a manually curated classification of proteins of know structures from the protein data Bank based on their structural and evolutionary relatedness. In SCOP, a protein domain is considered as an unit of evolution if it occurs independently or in combination with other domains on the basis of evidence from proteins of known structure. SCOP has a hierarchical classification scheme with the principal levels being family, superfamily, fold and class. Proteins clustered together into families are clearly evolutionarily related, usually detectable at sequence level. Proteins brought together into superfamilies although have low sequence identity, their structural and functional features suggest a common evolutionary origin. Superfamilies with similar topology, but without evidence for evolutionary relatedness are grouped under a fold. Folds are then classified into classes based on the secondary structure elements present.



We have considered only the first five classes (All-alpha, All-beta, alpha/beta, alpha+beta and Small proteins), the fold and the superfamily level of SCOP hierarchy for determining insertions. We excluded mono-domain proteins and considered chains which have at least two domains in them. In multi-domain proteins, while it is usual to have two domains linked in a linear fashion, i.e., the C-terminus of the first domain covalently linked to the N-terminus of the second domain, we looked for domains which are interrupted in the middle by the insertion of another domain. Thus, the second domain (insert) begins and ends inside the first domain (parent domain). The domains involved in insertions can come from the same or different SCOP superfamily.
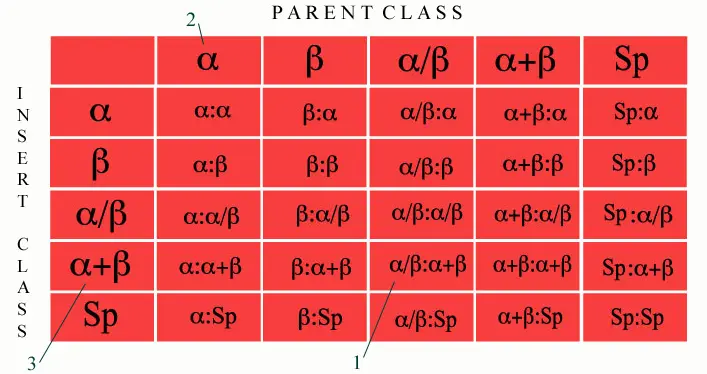
How can we obtain a list based on insertion combination?
We have provided a search facility where we have grouped insertions based on the combination of SCOP classes. For example, clicking the cell marked 1 will retrieve the list of entries where the parent domain belongs to alpha/beta class and the insert belongs to alpha+beta class.
The list of entries with a specific parent or insert class can also be obtained by clicking the individual classes on the top-most horizontal row for parent classes or the first vertical column for insert classes. For example, the cell marked 2 will retrieve all entries which have at least one parent domain belonging to All-alpha class while the clicking the cell marked 3 will retrieve all entries which have at least one insert domain belonging to alpha+beta class.
For each entry (chain) in the database, we provide the following information: the name of the protein, its biochemical function, Medline reference for the structure, the number of domains, their boundary (based on SCOP domain definition), sequence information, links to SCOP, CATH, FSSP, PDBSum and MMDB.